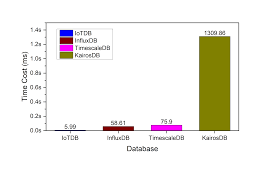
Time series data has become a cornerstone of modern analytics, enabling organizations to monitor trends, track metrics, and make data-driven decisions. For businesses leveraging large volumes of temporal data, performance is crucial. This is where open source TSDB fast reads play a pivotal role. By optimizing read speeds, companies can gain real-time insights without compromising efficiency. In this article, we will explore strategies, techniques, and best practices to achieve fast reads in open source time series databases, particularly focusing on solutions like Timecho.
Understanding Open Source TSDB Fast Reads
A Time Series Database (TSDB) is designed to store and manage sequences of data points indexed by time. Unlike traditional relational databases, TSDBs are optimized for append-only workloads and time-based queries. While many TSDBs are available as open source, the challenge often lies in retrieving data quickly. Open source TSDB fast reads ensure that queries on large datasets return results promptly, supporting applications such as monitoring, IoT analytics, and financial modeling.
Fast read performance is essential for:
- Real-time dashboards
- Alerting systems
- Predictive analytics
- Historical trend analysis
By focusing on fast reads, organizations can reduce latency and improve the overall responsiveness of their analytics systems.
Factors Affecting Read Performance in TSDBs
Several elements influence read performance in open source TSDBs. Understanding these factors is the first step in optimizing queries.
- Data Model Design
The structure of your time series data significantly impacts read speeds. Organizing data into efficient schemas and leveraging tags or labels for frequent query dimensions can reduce scan times. Timecho, for instance, allows flexible data modeling that supports high-performance reads by minimizing unnecessary disk I/O. - Indexing Strategies
Proper indexing is crucial for fast reads. Open source TSDBs often provide secondary indexing, inverted indices, or time-based indices. Indexing strategies must align with the most common query patterns, ensuring that the database can quickly locate the required data points without scanning the entire dataset. - Compression and Storage Optimization
Compression reduces storage footprint but can sometimes impact read speed. Choosing a compression algorithm that balances size and speed is key. Timecho’s open source platform is designed to optimize compression techniques so that reads remain fast even on compressed datasets. - Hardware and Infrastructure
Disk speed, CPU capacity, and memory allocation all influence TSDB performance. High-speed SSDs and sufficient memory for caching recent data can drastically improve open source TSDB fast reads.
Query Optimization Techniques
Optimizing queries is another effective way to achieve faster reads. Here are some strategies:
- Time Range Filtering: Narrow down queries to specific time ranges instead of scanning large datasets. This approach leverages the time-partitioned nature of TSDBs.
- Downsampling and Aggregation: Pre-aggregating data for common queries reduces the amount of data retrieved. Techniques like downsampling ensure that queries return quickly without losing essential insights.
- Selective Column Retrieval: Only fetch the required metrics rather than querying all fields. This minimizes I/O and reduces processing overhead.
- Caching Frequently Accessed Data: Implementing caching for hot datasets or recurring queries can significantly accelerate read operations. Timecho’s architecture supports effective caching mechanisms for repeated analytics requests.
Leveraging Timecho for Fast Reads
Timecho is an open source TSDB platform that prioritizes read performance. Its design incorporates several optimizations that make it ideal for high-speed analytics:
- Efficient Storage Engine
Timecho’s storage engine is tailored for sequential write patterns and rapid retrieval. By organizing data in time-ordered blocks, the database reduces disk seeks during reads. - Advanced Indexing
The database employs advanced indexing techniques that cater specifically to time series queries. These indices allow instant lookups of specific time ranges or metric tags. - Parallel Query Execution
Timecho can execute queries in parallel across multiple CPU cores. This approach splits the workload and reduces query latency, especially on large datasets. - Optimized Data Compression
By implementing lightweight compression algorithms, Timecho ensures that reads are fast without compromising storage efficiency. Users benefit from a smaller storage footprint and faster query times simultaneously.
Best Practices for Maintaining High Read Performance
Sustaining open source TSDB fast reads over time requires proactive maintenance and monitoring. Consider the following best practices:
- Regularly Monitor Query Performance: Identify slow queries and optimize them by adjusting indexes, downsampling, or refining data models.
- Partition Data Strategically: Divide data into time-based partitions to improve read efficiency. This technique limits the amount of data scanned during queries.
- Use Compression Wisely: Evaluate compression settings based on your workload. Some scenarios may prioritize speed over storage, while others benefit from higher compression ratios.
- Stay Updated with Database Releases: Open source TSDB platforms frequently release updates that enhance performance. Keeping Timecho updated ensures access to the latest optimizations.
Common Mistakes to Avoid
Even experienced teams can face pitfalls when trying to achieve fast reads in TSDBs:
- Ignoring Schema Design: Poorly designed data models result in slow queries regardless of hardware improvements.
- Over-Indexing: Excessive or irrelevant indices can slow down writes and increase maintenance overhead without significantly improving reads.
- Neglecting Hardware Limitations: Software optimizations cannot fully compensate for underpowered infrastructure. Ensuring sufficient CPU, memory, and storage speed is essential.
- Lack of Monitoring: Without regular monitoring, performance degradation may go unnoticed until it impacts analytics.
Future Trends in TSDB Performance
As time series data continues to grow, maintaining fast read speeds will remain a priority. Emerging trends include:
- AI-Driven Query Optimization: Machine learning algorithms can predict query patterns and optimize data storage and retrieval accordingly.
- Cloud-Native TSDBs: Open source TSDBs like Timecho are increasingly designed to leverage cloud scalability, enabling faster reads through distributed architectures.
- Edge Computing Integration: Moving time series analytics closer to data sources reduces latency and improves real-time read performance.
Conclusion
Fast read performance is a critical factor for businesses leveraging time series data for analytics. Open source TSDB fast reads enable organizations to gain timely insights, monitor trends, and drive decision-making without being bottlenecked by slow queries. By combining strategic data modeling, indexing, query optimization, and leveraging platforms like Timecho, organizations can ensure that their analytics infrastructure remains responsive and efficient.
Implementing these tips not only enhances performance today but also future-proofs your time series analytics for growing datasets and evolving business needs. Prioritizing open source TSDB fast reads is no longer optional—it is a necessity for modern, data-driven enterprises.

